分解一张图片
CNN的第一步是把图片分成小块。我们选择一个宽度和高度来定义一个滤波器。
滤波器会照在图片的小块 patch (图像区块)上。这些 patches 的大小与滤波器一样大。
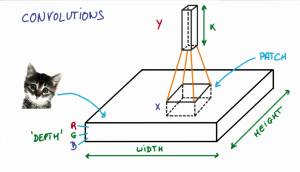
如之前视频所示,CNN用滤波器来把图片分割成更小的 patches,patch 的大小跟滤波器大小相同。
我们可以在水平方向,或者竖直方向滑动滤波器对图片的不同部分进行聚焦。
滤波器滑动的间隔被称作’stride’(步长)。他是你,作为工程师,可以调节的一个超参数。增大 stride 会通过减少每层观察总 patches 的数量来减小你模型的大小。
让我们看一个例子,在这个放大的狗图片中,我们从红框开始,我们滤波器的高和宽决定了这个正方形的大小。

金色巡回犬图片的一块
然后我们向右把方块移动一个给定的步长(这里是2),得到另一块。

我们把方块向右移动两个像素,得到另一个patch。
这里最重要的是我们把相邻的像素聚在一起,把他们视作一个集合。
在传统的神经网络中(如前馈神经网络),没有考虑这种邻近性的特征。在前馈网络中(Feedforward Neural Network),我们把输入图片中的每个像素直接与下一层的神经元相连,因此忽略了像素之间的邻近信息。而这种邻近信息恰恰是至关重要的。
要利用这种临近结构,我们的CNN就要学习如何分类临近模式,例如图片中的形状和物体。
滤波器深度
通常来说会同时使用多个滤波器,不同滤波器提取一个 patch 的不同特性。例如,一个滤波器寻找特定颜色,另一个寻找特定物体的特定形状。卷积层滤波器的数量被称为滤波器深度。
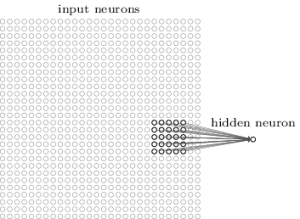
上述例子中,一个 patch 与下一层的神经元相连
来源: MIchael Neilsen
每一个 patch 连接到多少神经元呢?
这取决于我们滤波器的深度,如果我们的深度是 k,我们把每个 patch 与下一层的 k 个神经元相连。这样我们下一层的高度就是 k,如下图所示。实际操作中,k是一个我们可以调节的超参数,大多数的CNNs倾向于选择相同的起始值。
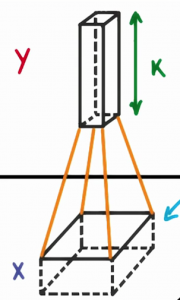
滤波器的深度为k,与下次的k个神经元相连
为什么我们把一个 patch 与下一层的多个神经元相连呢?一个神经元不够好吗?
多个神经元的意义在于使用多个神经元可以分别提取和保存每个patch的多个特点。
例如,一个 patch 可能包括白牙,金色的须,红舌头的一部分。在这种情况下,我们想要一个深度至少为3的滤波器,一个为了牙,一个为了须,一个为舌头。
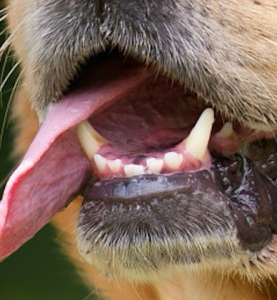
这个狗的patch 有很多有意思的特征需要提取。包括牙、须以及粉红色的舌头。
一个patch连接有多个神经元可以保证我们的 CNNs 学会提取任何它觉得重要的特征。
记住,CNN并没有被规定寻找特定特征。与之相反,它会自动学习到那些值得注意的特征。