我们将在MNIST数据集中来训练生成对抗网络(GAN),并使用训练后的网络,生成一个新的手写数字。
GANS是由Ian Goodfellow 等其他人在2014年首次提出,当时他在Yoshua Bengio教授的实验室做研究。此后,人气爆棚,下面有一些例子:
- Pix2Pix 非常酷,你画一个东西,它能够创建一幅图像
- CycleGAN 也很棒,比如实现让马看起来像斑马,真的很厉害
- A whole list
GAN背后的意思是你要有两个网络,一个是生成器G还有一个就是辨别器D,他们相互竞争。生成器将伪造的数据,让他们看起来更像真实数据,传递给辨别器。辨别器可以根据看到数据努力判定并预测它接收到的数据是真的还是假的。所以生成器将假数据传递给辨别器,而你将真实数据传递给辨别器,然后,由辨别器来判断是真是假。当你在训练时,生成器会学习生成图像和数据,让他们看起来尽量和真实数据一样。在这个过程中,他会学习模仿实际真实数据的概率分布。通过这种方式,你可以生成与真实世界中看起来一样的新图像、新数据。那么按照惯例,我们在这里要使用Tensorflow实现一些神经网络,来作为生成器和辨别器。
生成器经过训练以欺骗辨别器,它希望输出看起来尽可能接近实际数据的数据。辨别器经过训练可以确定哪些数据是真实的,哪些是假的。最终,生成器将生成很真实的数据,传送到辨别器。
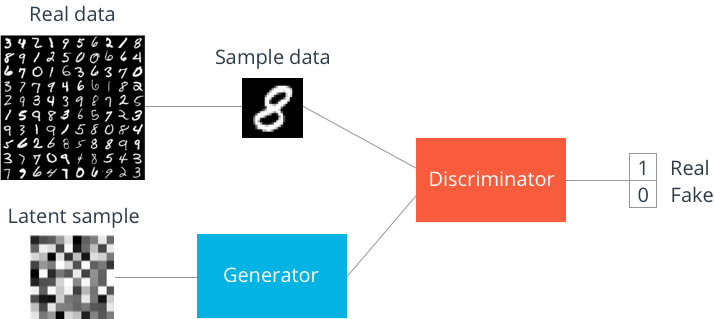
上图显示的是GAN的结构,使用MNIST图像作为数据。潜在样本是生成器用来构造伪造图像的随机向量。当生成器通过训练学习时,它会计算出如何将这些随机向量映射为可以欺骗辨别器的可识别图像。
辨别器的输出是一个S形函数,其中0表示假图像,1表示真实图像。如果您只对生成新图像感兴趣,可以在训练后丢弃鉴别器。 现在,让我们看看我们如何在TensorFlow中构建这些东西。
|
1 2 3 4 5 6 7 |
%matplotlib inline import pickle as pkl import numpy as np import tensorflow as tf import matplotlib.pyplot as plt |
首先,请在此导入包和数据集
|
1 2 |
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data') |
输出
|
1 2 3 4 |
Extracting MNIST_data/train-images-idx3-ubyte.gz Extracting MNIST_data/train-labels-idx1-ubyte.gz Extracting MNIST_data/t10k-images-idx3-ubyte.gz Extracting MNIST_data/t10k-labels-idx1-ubyte.gz |
模型输入
首先,我们需要为图形创建输入。 我们需要两个输入,一个用于辨别器,一个用于生成器。 这里我们将调用辨别器输入inputs_real和生成器输入inputs_z。 我们将为他们分配适合每个网络的尺寸。其中real_dim作为真实输入的维度,z_dim作为z输入的维度。
|
1 2 3 4 5 |
def model_inputs(real_dim, z_dim): inputs_real = tf.placeholder(tf.float32, (None, real_dim), name='input_real') inputs_z = tf.placeholder(tf.float32, (None, z_dim), name='input_z') return inputs_real, inputs_z |
首先,我们定义输入张量,使用tf.placeholder方法,设定float32数据类型,然后大小为任意批量大小,接下来设置我们真实数据的维度real_dim,我们将用它作为真实输入。
然后,是z输入,这是要进入生成器的向量。接下来的一样,tf.placeholder方法,设定float32数据类型,然后大小为任意批量大小,将进入生成器的向量的维度。
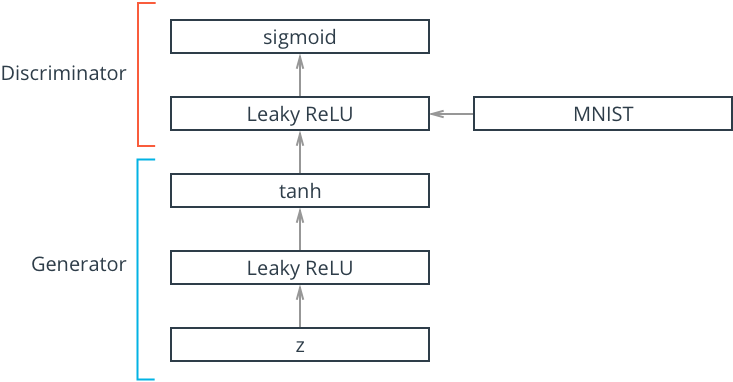
在这里,我们将构建生成器网络。这张图显示了,整个网络的样子,这里的生成器是我们的输入z,他只是一个随机向量,一种随机白噪声,我们会将其传入生成器。然后,生成器学习如何将这个随机向量z转变为tanh层中的图像,所以,我们在生成器中输入z,他将进入Leaky ReLU层,Leaky ReLU类似于普通的ReLU,你知道ReLU的负数端斜率为0,而Leaky ReLU的区别在于其负数端有一个较小的斜率,比如 0.01;正数端是相同的。tanh函数类似于sigmoid会将输入缩放到某个范围,但是tanh的输出范围为-1到1。这意味着,我们需要做转换工作,需要转换MNIST图像,将MNIST图像取值范围在-1到1之间,然后将其传入辨别器网络。
现在,只有生成器这部分,是你要完成的。
Variable Scope
你其中要做的一件事,就是用tf.variable_scope。第一步,我们要为生成器和辨别器中的不同变量命名,你可以用name_scope来完成。但如果使用variable_scope你可以设置它,下次再次调用变量。我想说的是,有时候我们需要再次创建网络。以生成器为例:我们想要训练它,但也想从中取样。对于辨别器而言,我们要放入假图像和真实图像。那么,当我们做这些不同的事情,例如将假图像和真实图像放入辨别器里,我们希望重复使用之前的变量,也就是之前创建网络时所用的变量,因为如果不重用变量,当你运行函数,再次创建网络时,他会创建全新的变量,这并不是我们想要的。我们希望对真实和伪造的输入图像,使用相同的变量,要这样做,你只需要将代码放在tf.variable中,给出scope_name。这个例子中我们会对不同的网络,使用生成器和辨别器。这里设置reuse参数,如果你想创建新的网络,将reuse设为False。如果你想重用变量,将他设为True。
|
1 2 |
with tf.variable_scope('scope_name', reuse=False): # code here |
Leaky ReLU
像我们之前讲到的,我们要使用Leaky ReLU,对于普通的ReLu你可以使用tf.maximum创建,但Tensorflow并没有自带Leaky ReLU函数,所以我们要自己创建,可以使用tf.maximum来创建,这里我们可以将函数设为max(a*x,x)。在这里 a只是一个控制尺度的参数。他控制负数端输出值的大小。通常情况下会设的非常下,比如 0.01 。那么他的意义就是:当x为负时,我们将取这个乘积,因为他更大。当x为正数时,我们将取值x,因为他更大。
f(x)=max(α∗x,x)
Tanh Output
最后,我们需要得到生成器的tanh输出,下面函数中,想要输出tanh,以获取新的图像。 我们要返回logits,并传入tf.nn.sigmoid_cross_entroy_with_logites之中,
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def generator(z, out_dim, n_units=128, reuse=False, alpha=0.01): with tf.variable_scope('generator', reuse=reuse): # Hidden layer h1 = tf.layers.dense(z, n_units, activation=None) # Leaky ReLU h1 = tf.maximum(alpha * h1, h1) # Logits and tanh output logits = tf.layers.dense(h1, out_dim, activation=None) out = tf.tanh(logits) return out |
你有隐藏层,需要将他变成线性层,然后传递给Leaky ReLU,你可以在这里执行计算获取logit和tanh的输出,然后返回out和logit。
上面的生成器,首先我们将它包裹在variable_scope中,使用generator作为作用域的名称,所以基本上所有的变量,都将以generator开头,这里我们选择重用,因为它将告诉作用域,重用本网络的变量。那么我们从函数参数中获得reuse。将他传递到这里。默认为false,如果我们让张量通过它,他会为我们创建一个新的网络。但是我们将他设置为true,这样你让另一个张量通过它,他就会重用之前创建的变量。对于隐藏层,我们使用tf.layers.dense进行构建,这是一个全链接层,你可以直接使用层模块,因为他是高级的,他会为你执行所有的权重初始化,那么我们传入z输入张量,并定义单元数量这是一个自变量,默认设置为128.他们不使用激活,所以只是一个线性层,之所以这么做,因为tensorflow没有leaky ReLU函数。所以我们得自己执行计算,这也意味着我们只能获得这层的线性输出。
然后,使他通过一些函数,来为我们计算Leaky ReLU。要这样做我们使用tf.maximun , alpha是一个比较下的数字,你要用它乘以这层的输入。如果h1为正,比如说+1,alpha*h1 是o.o1 ,h1是1,因为alpha默认为0.01。如果h1这个为负,那么最大值就是alpha*h1 。这样你就可以计算Leaky ReLU,一般情况下,如果是正输入,你将得到与输入相同的值,如果是负输入,你将得到比输入小的负值。
在这里我们使用tf.layers.dense获取logits,传入我们的ReLU输出、out_dim,然后使用tf.tanh创建生成器的输出。
Discriminator 辨别器
基本上和生成器相同,只是我们使用的是sigmoid输出层,所以这里我们要再次使用tf.variable_scope,定义隐藏层,Leaky ReLU、logit和输出。在强调一些辨别器的输出,应该使用sigmoid。因为我们要让辨别器,给出非真即假的选择,1或0.
|
1 2 3 4 5 6 7 8 9 10 11 |
def discriminator(x, n_units=128, reuse=False, alpha=0.01): with tf.variable_scope('discriminator', reuse=reuse): # Hidden layer h1 = tf.layers.dense(x, n_units, activation=None) # Leaky ReLU h1 = tf.maximum(alpha * h1, h1) logits = tf.layers.dense(h1, 1, activation=None) out = tf.sigmoid(logits) return out, logits |
辨别器的代码和上面的生成器差不多,唯一的不同之处在于我们使用sigmoid作为输出。
超参数
|
1 2 3 4 5 6 7 8 9 10 11 |
# Size of input image to discriminator 图片到辨别器大小 input_size = 784 # 28*28而来,是MNIST图像被平面化了 # Size of latent vector to generator z_size = 100 # 传入生成器的本征向量大小,这只是随机生成的一种噪音,将他传入生成器,生成图像 # Sizes of hidden layers in generator and discriminator g_hidden_size = 128 # 这两项是生成器和辨别器隐藏层大小 d_hidden_size = 128 # Leak factor for leaky ReLU alpha = 0.01 # Smoothing smooth = 0.1 |
需要记住的一点是,当你在构建神经网络时。如果你的网络中有非线性隐藏层,它可以作为通用函数逼近器。这就是为什么我们将隐藏层与非线性激活函数 leaky ReLU 一起使用。说到 leaky ReLU,alpha 是渗漏系数,你可以将这些传入生成器和辨别器网络中。
smooth是是标签平滑化的参数,我们下面会讲到。
构建网络
这里你将使用之前的函数,你要获取真实的图像的输入,从你的模型输入函数获得本征向量输入,然后创建生成器网络和辨别器网络,d_model_real为真实图像的输出,d_logits_real为真实图像的logits。d_model_fake为假图像的输出,d_logits_fake为假图像的logits。我们要从生成器获取假图像,也就是g_model,然后将将假图像传入辨别器,来获得输出d_model_fake。由于我们想对真实图像和假图像,使用相同的权重,我们需要将reuse设为ture。
所以我们的辨别器定义为discriminator(g_model, reuse=True)
|
1 2 3 4 5 6 7 8 9 10 |
tf.reset_default_graph() # Create our input placeholders input_real, input_z = model_inputs(input_size, z_size) # Build the model g_model = generator(input_z, input_size, n_units=n_units, alpha=alpha) # g_model is the generator output d_model_real, d_logits_real = discriminator(input_real, n_units=n_units, alpha=alpha) d_model_fake, d_logits_fake = discriminator(g_model, reuse=True, n_units=n_units, alpha=alpha) |
好的,我来讲解上面的代码:
我们首先使用tf.reset_default_graph(),但它的作用基本上是擦除,你之前定义的任何图,直接重置它,然后当你调用它时,会构建一个新图。如果没有它,当你调用后面的函数时,你只会构建越来越大的图,然后变得很混乱,并最终崩溃。所以每次当你运行这部分时,记得将它放到这里。
下面我们使用输入大小,调用model_inputs这个input_size,input_size是我们MNIST图像的大小,实际上MNIST图像将被扁平化,成为784维长的向量。然后传入生成器的向量大小z_size,我们会得到真图输入的张量和另一个张量,它是进入生成器的本征向量输入。
下面,我们使用input_z来创建我们的生成器网络,这里的g_model是我们生成器的tanh输出,然后这是logit。
接下来,我们构建辨别器,传入真图输入向量input_real,获得sigmoid输出和logit,记住sigmoid的作用就是尝试决定这是真图还是假图,真则输出1,假则输出0.
然后我们还将传入假图像,假图像来自生成器,也就是这个 g_model,生成器的 tanh 输出,是一个我们将传递给辨别器的图像,此图像将尝试欺骗辨别器。
让后者认为它是真的,由于我们想对真图像和假图像,使用相同的权重 我们需要在此将 reuse 设为 true,然后传入来自生成器的假图像。
好的 接下来我们将讨论,此 GAN 网络的损失和优化器。
Discriminator and Generator Losses 辨别器和生成器的损失
这里你将实施代码,来获得辨别器和生成器损失,在GAN中,我们实际要做的是,同时训练辨别器和生成器网络,我们需要这两个不同网络的损失,对于辨别器,总损失是真实图像和假图像损失之和,记得在前面的代码块中,我们定义了真实图像和假图像的输出,所以我们可以使用这些来获得损失。这里我们使用sigmoid交叉熵
|
1 |
tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels)) |
和往常一样,你只需传入logits,传入标签,然后为了获得传入的所有样本的总损失,我们使用tf.reduce_mean。
对于真实图像,我们使用来自真实图像的logits,我们已在上面定义,对于标签,由于这些是真实图像,而且我们想让辨别器直到他们是真的,我们希望标签(真图的输出为1)全部为1。
为了帮助辨别器更好的泛化,我们要执行一个叫做标签平滑的操作,我们要做的是创建一个叫做smooth的参数,它略小于1,然后我们用标签乘以该参数;例如 如果smooth是0.9,然后你用标签乘以0.9,那么你的实际标签将是0.9.
假数据的辨别器损失也类似,那么我们再次获取logits虚假图像的d_logits,我们在上面做了定义,然后我们设定这些标签(也就是假输出为0)全部为0,也就是说0,对应假图像,所以当遇到假图时,我们希望标签为0。最后,对于生成器我们再次使用d_logits_fake,但这次,我们的标签全部为1,因为记得我们想让生成器欺骗辨别器,所以我们想让辨别器以为假图是真的。再一次1对应真,我们的生成器,让辨别器将所有这些都视为真的。
在这里我们使用tf.nn.sigmoid_cross_entropy_with_logits 传入适当的logits和标签,来计算所有损失。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Calculate losses d_loss_real = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1 - smooth))) d_loss_fake = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.zeros_like(d_logits_real))) d_loss = d_loss_real + d_loss_fake g_loss = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.ones_like(d_logits_fake))) |
下面我们来讲解上面的代码:
我们在这里看到的时网络的损失, 这是我们用来训练模型的东西。
d_loss_real = tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1 – smooth)))
首先,是真实的图像的辨别器损失,我们使用tf.reduce_mean来获取我们传入的所有图像的损失平均值,里面使用tf.nn.sigmoid_cross_entropy_with_logits来实际计算该损失,里面传入logits真图的logits,然后是标签labels,我们希望这些均为1,使用tf.ones_like来获得与d_logits_real形状相同的为1的张量,然后进行标签平滑化,所以要给他乘以(1 – smooth)
接下来,是假图像的损失,别的差不多,但是labels我们希望为0,因为他是假图,所以使用tf.zeros_like(d_logits_real)。
获取总损失,就需要将它们加起来。
对于生成器的损失,我们同样使用假数据logits:d_logits_fake。但是这次我们想让辨别器认为他是真的,所以我们想让辨别器对这些假图输出1,所以labels应该为1,使用tf.ones_like(d_logits_fake)
优化器
我们需要做的最后一件事,就是构建优化器,和往常一样,我们将在这里使用Adam优化器,因为它非常好用,我们要做的就是,分别对生成器训练辨别器变量。首先,你需要获取所有的可训练的变量,要这样做,你只需使用tf.trainable_variables() 。他的作用是返回,所有可训练的变量对象的,一个列表,获取列表后,你可遍历它,并对这些变量对象执行操作。
对于生成器优化器,我们只需要生成器变量,你可能记得,我们之前使用variable_scope命名所有的生成器变量,使他们以generator一词开头,以便我们遍历得到的,可训练变量的列表。然后创建一个新的列表,仅包含以generator开头的变量。这样我们的生成器图中,将只有可训练的变量,然后我们可以将它传入Adam优化器中,仅训练那些有生成器损失的变量,然后你基本上可以对辨别器,执行相同的操作,即获得所有以discriminator开头的变量,然后在优化器,即tf.train.AdamOptimizer()中,调用minimize方法时,传入变量列表,仅传入那些将在训练中更新的变量,那么我们在下面实现优化器
|
1 2 3 4 5 6 7 8 9 10 |
# Optimizers learning_rate = 0.002 # Get the trainable_variables, split into G and D parts t_vars = tf.trainable_variables() g_vars = [var for var in t_vars if var.name.startswith('generator')] d_vars = [var for var in t_vars if var.name.startswith('discriminator')] d_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(d_loss, var_list=d_vars) g_train_opt = tf.train.AdamOptimizer(learning_rate).minimize(g_loss, var_list=g_vars) |
像我之前所说,我们要将可训练变量,分为生成器和辨别器两部分,因为我们将用不同的优化器,来分别训练这些变量。那么要获取所有可训练变量,只需执行tf.trainable_variables(),他会返回一个列表,显示你的图表中可训练的所有变量。
也就是说此列表包含变量对象,这些变量对象有属性名,即“字符串”,生成器我们用了variable_scope始终以generator开头,所以可以将他们分成两个部分。
然后,我们将他传入到优化器中,给出优化器学习率,然后我们将最小化辨别器损失,传入var_list=d_vars 辨别器变量。生成器同理。
训练你的模型
这里是我们用于训练网络的代码,与你看到的其他代码很相似。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
batch_size = 100 epochs = 100 samples = [] losses = [] # Only save generator variables saver = tf.train.Saver(var_list=g_vars) with tf.Session() as sess: # 与往常一样,我们先开始一个会话,他会初始化我们可以开始训练的所有变量 sess.run(tf.global_variables_initializer()) for e in range(epochs): # 循环训练批次 for ii in range(mnist.train.num_examples//batch_size): # 获取批次,他会给我们一批数据,一个批次是一个元祖。 # 第一个元素是我们的图像,第二个元素就是标签,但是我们不关心标签,只获得图像 batch = mnist.train.next_batch(batch_size) # Get images, reshape and rescale to pass to D # 只获得第0批,他会像我们提供图像实际上是28*28的数组 # 我们想将他们展开成张量,并出传入我们的辨别器中 # reshape是重塑它,批量大小784=28*28而来 # 对于批量图像,生成器使用tanh输出,这意味着图像会缩放到-1到1范围内 batch_images = batch[0].reshape((batch_size, 784)) # 由于NNIST图像实际上是0到1,我们必须重新缩放, # 下面的batch_images*2 - 1会进入辨别器,真实图片重新缩放为-1到1 batch_images = batch_images*2 - 1 # Sample random noise for G # 这里获取生成器输入,生成器本征向量,这里从-1到1的随机噪声 batch_z = np.random.uniform(-1, 1, size=(batch_size, z_size)) # Run optimizers # 运行优化器 传入input_real真实图像,然后传入本征向量input_z, # 进入生成器生成假图,我们的d_train_opt通过训练,不断降低d_loss # d_loss是真实图像损失和假图损失之和,所要对真图和假图优化 _ = sess.run(d_train_opt, feed_dict={input_real: batch_images, input_z: batch_z}) # 对于生成器我们只需要传入本征向量 _ = sess.run(g_train_opt, feed_dict={input_z: batch_z}) # At the end of each epoch, get the losses and print them out # 这里我们是跟踪网络训练性能,每个epoch获取辨别器和生成器各自损失 train_loss_d = sess.run(d_loss, {input_z: batch_z, input_real: batch_images}) train_loss_g = g_loss.eval({input_z: batch_z}) print("Epoch {}/{}...".format(e+1, epochs), "Discriminator Loss: {:.4f}...".format(train_loss_d), "Generator Loss: {:.4f}".format(train_loss_g)) # Save losses to view after training losses.append((train_loss_d, train_loss_g)) # Sample from generator as we're training for viewing afterwards sample_z = np.random.uniform(-1, 1, size=(16, z_size)) gen_samples = sess.run( generator(input_z, input_size, reuse=True), feed_dict={input_z: sample_z}) samples.append(gen_samples) saver.save(sess, './checkpoints/generator.ckpt') # Save training generator samples with open('train_samples.pkl', 'wb') as f: pkl.dump(samples, f) |
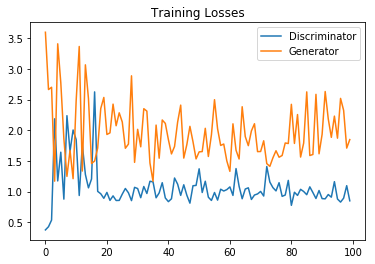
训练损失
这段代码输出的就是训练损失图,损失一般都是刚开始高,然后降低,最后,随着训练会变得平缓
|
1 2 3 4 5 6 |
fig, ax = plt.subplots() losses = np.array(losses) plt.plot(losses.T[0], label='Discriminator') plt.plot(losses.T[1], label='Generator') plt.title("Training Losses") plt.legend() |
这里是100个epoch后的结果,如果训练更久,效果更好
训练生成器样本
下面用来查看我们保存的样本的一些代码,上面的代码实际上将样本保存在了磁盘上
|
1 2 3 4 5 6 7 8 |
def view_samples(epoch, samples): fig, axes = plt.subplots(figsize=(7,7), nrows=4, ncols=4, sharey=True, sharex=True) for ax, img in zip(axes.flatten(), samples[epoch]): ax.xaxis.set_visible(False) ax.yaxis.set_visible(False) im = ax.imshow(img.reshape((28,28)), cmap='Greys_r') return fig, axes |
加载之前保存的训练样本
|
1 2 3 |
# Load samples from generator taken while training with open('train_samples.pkl', 'rb') as f: samples = pkl.load(f) |
|
1 |
_ = view_samples(-1, samples) |
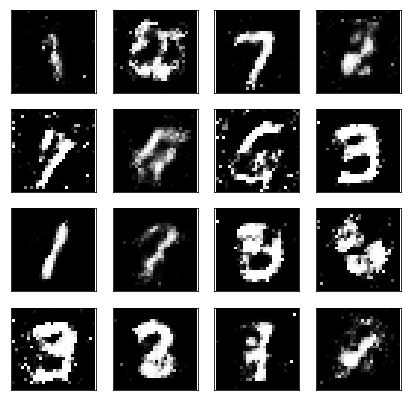
这基本上是我们看到的结果,这是最后依次epoch从生成器获得的样本。这时生成器已经训练了一会儿,我们可以看到它实际产生了一些比较清晰的数字,这里有一个7,3,1有的像2,有的有些奇怪,但总体而言,他们产生了一些不错的数字。不过这只是它生成图像的一个较小样本,你会看到一些杂乱的东西,一些噪声。
如果我们训练生成器时间更久的话,这些奇怪的图就会消失,会获得清晰的数字。
下面展示每10次epoch产生的生成器图像,这只是向你展示生成器训练进度的一种方式,刚开始所有的东西,都是一团白色的噪声。
然后不断学习,将边缘变黑,不断有模糊的数字形状,直到清晰。
|
1 2 3 4 5 6 7 8 |
rows, cols = 10, 6 fig, axes = plt.subplots(figsize=(7,12), nrows=rows, ncols=cols, sharex=True, sharey=True) for sample, ax_row in zip(samples[::int(len(samples)/rows)], axes): for img, ax in zip(sample[::int(len(sample)/cols)], ax_row): ax.imshow(img.reshape((28,28)), cmap='Greys_r') ax.xaxis.set_visible(False) ax.yaxis.set_visible(False) |

从生成器采样
现在我们已经训练好了生成器,我们可以放入新的向量,得到新的图像
|
1 2 3 4 5 6 7 8 9 10 |
saver = tf.train.Saver(var_list=g_vars) with tf.Session() as sess: # 用来加载我们从训练中保存的检查点,生成一些新的本征向量,将这些放入生成器 # 并获得一些可以看到的新图像,这里有非常清晰的0、1、7 saver.restore(sess, tf.train.latest_checkpoint('checkpoints')) sample_z = np.random.uniform(-1, 1, size=(16, z_size)) gen_samples = sess.run( generator(input_z, input_size, reuse=True), feed_dict={input_z: sample_z}) _ = view_samples(0, [gen_samples]) |
