在此 notebook 中,我们将构建一个可以通过强化学习学会玩游戏的神经网络。具体而言,我们将使用 QQ-学习训练智能体玩一个叫做 Cart-Pole 的游戏。在此游戏中,小车上有一个可以自由摆动的杆子。小车可以向左和向右移动,目标是尽量长时间地使杆子保持笔直。
DQN 改进
深度Q学习算法
该算法中有两个交错的主要流程。
第一个流程是对环境取样,方法是执行动作,并以回放存储器的形式,存储观察的经验元祖。 read more
Q-Learning Update和固定Q目标
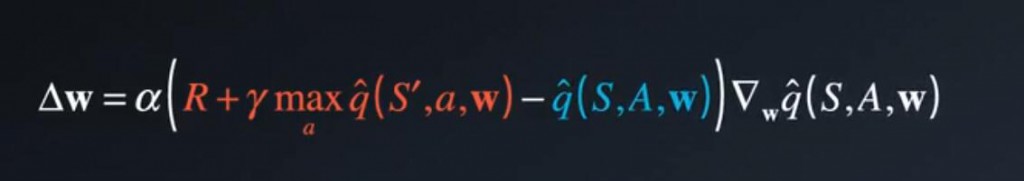
Q学习很容易受到一种联系的影响,Q学习是一种时间差分(TD)学习,这里红色部分:R + y * 下个状态的最大潜在值。称之为TD目标。 read more
强化学习-蒙特卡洛方法预测动作值
给一个策略π,预测 qπ。在动态规划中,我们可以使用状态值函数获取动作值函数: read more
强化学习-蒙特卡洛异同策略方法
智能体通过遵循某个策略与环境互动,并计算该策略的函数,就是异同策略方法。再详细讲解该算法之前,我们先来了解一个实例。 read more
深度卷积对抗网络
深度卷积对抗网络简称DCGAN,这些GAN给你之前使用MNIST数据库构建差不多,但是这次的生成器和辨别器用神经网络构建,有关于DCGAN原始论文请看:https://arxiv.org/pdf/1511.06434.pdf。他的技术性不是特别强,并提供了关于这些东西训练的一些好建议。确保你在构建过程中,阅读它。 read more
生成对抗网络
我们将在MNIST数据集中来训练生成对抗网络(GAN),并使用训练后的网络,生成一个新的手写数字。 read more
BasicLSTMCell
class BasicLSTMCell(RNNCell):
基本的LSTM循环网络单元 read more
解决 dlerror: cublasCreate_v2 not found
在windows10使用tensorflow1.0.0和python3.5的环境下,我的cuda使用的9.0。 read more